Data Ingestion
Populating our Data
Now that we have the elasticsearch cluster up and running, lets try ingesting some documents.
|
We’ll ingest Red Hat product documentation for this demonstration. Remember that RAG is flexible and can use various data sources, like live web data (similar to how Perplexity AI works). |
Executing the ingestion pipeline
-
From the
composer-ai-appsnamespace inside of the OpenShift Web Console navigate to thePipelines>Pipelinessection and locate theingestion-pipelinepipeline.Click on the
…on the right and clickStart.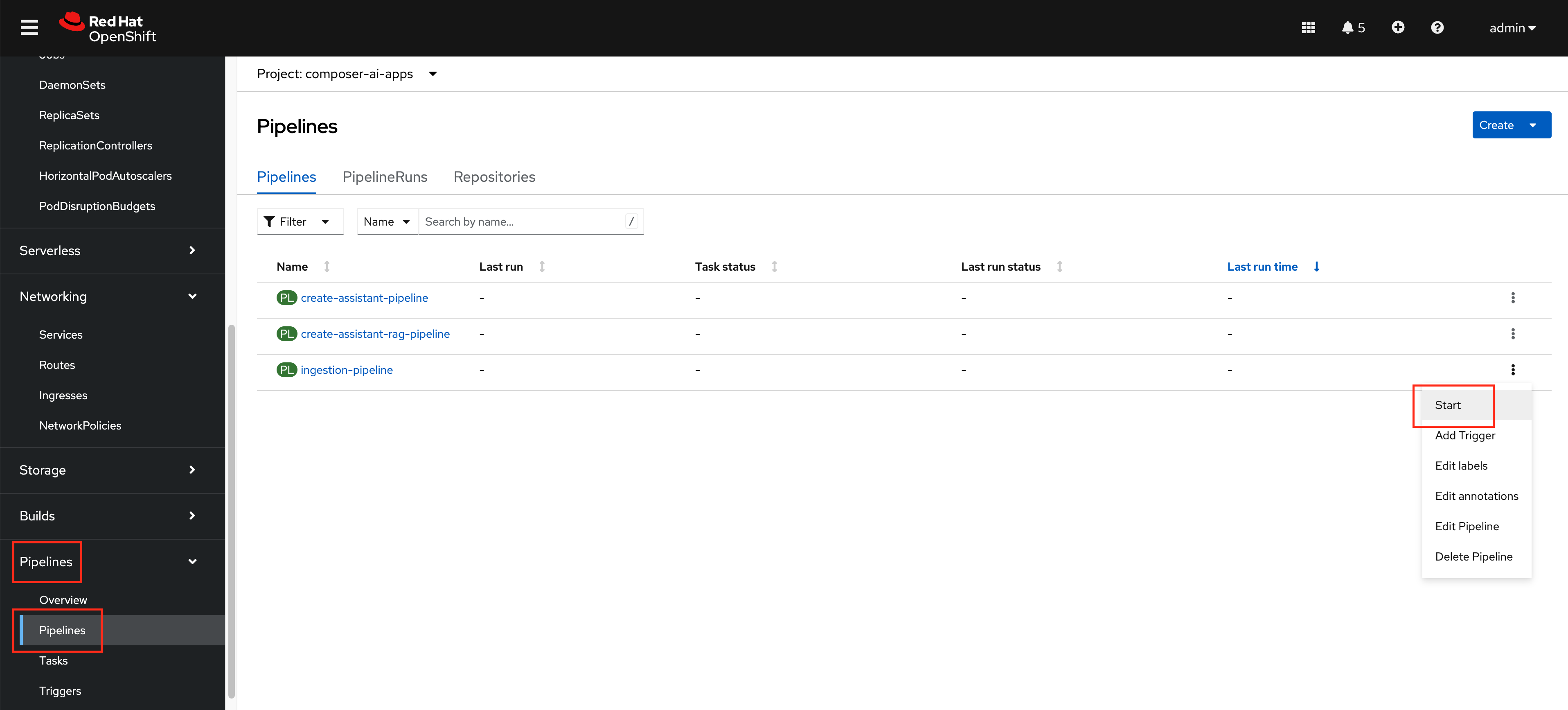
-
Update the
GIT_REVISIONfield tolabThe
labbranch reduces list of documents ingested to only includ Red Hat Openshift AI Documentation. We are using the pipeline in order to speed up the process. If you wish to try this pipeline on your own or test some of the other product assistants, feel free to leveragemain. -
Leave all of the default options except for the
source.Set
sourcetoVolumeClaimTemplateand start the pipeline.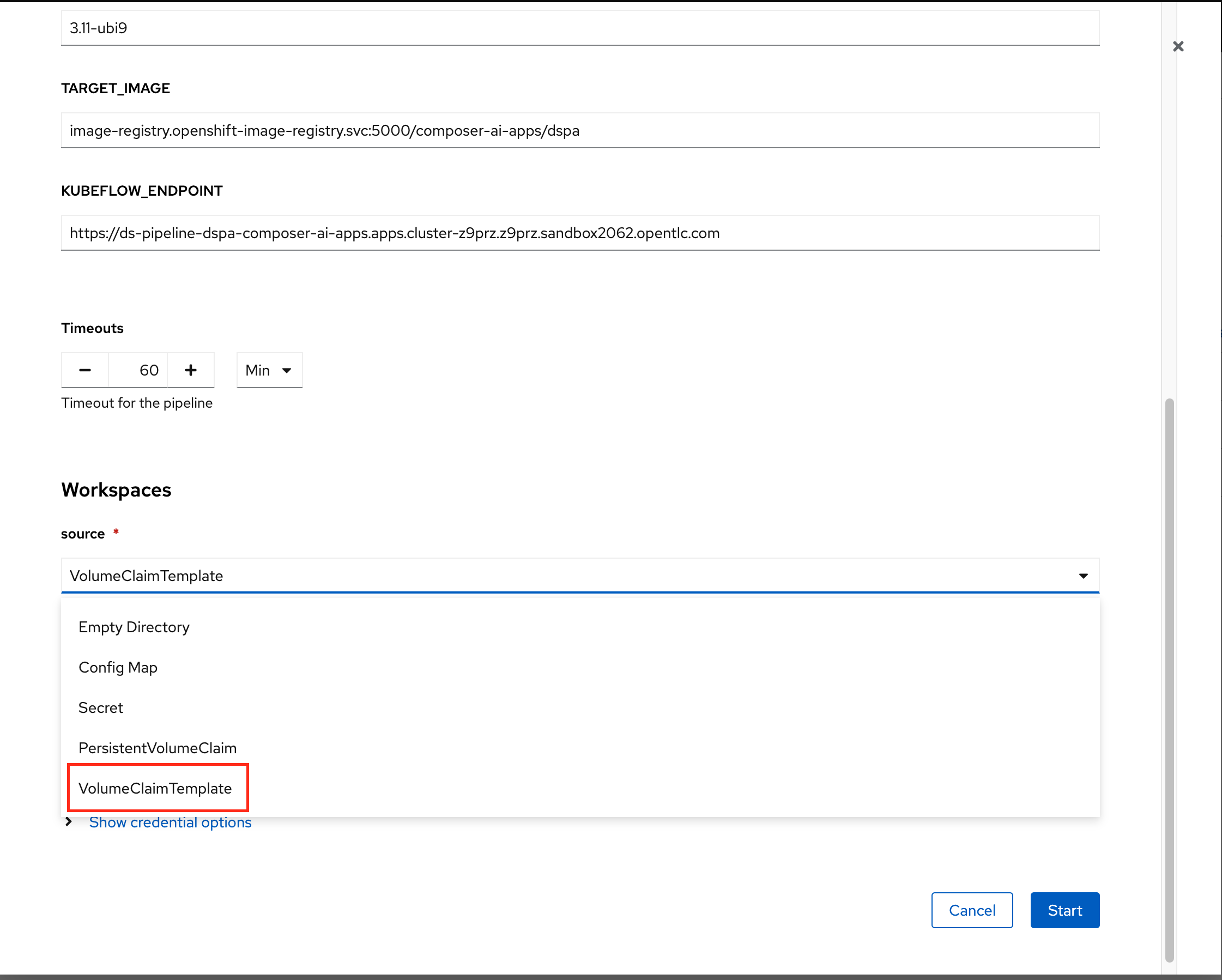
-
This Tekton pipeline will create and initiate the data science pipelines within RHOAI.
Wait for the execute-kubeflow-pipeline task to complete.
-
A new pipeline run will begin that will build an image containing our ingestion pipeline for Data Science Pipelines and initiate it. Wait for the
execute-kubeflow-pipelinetask to complete.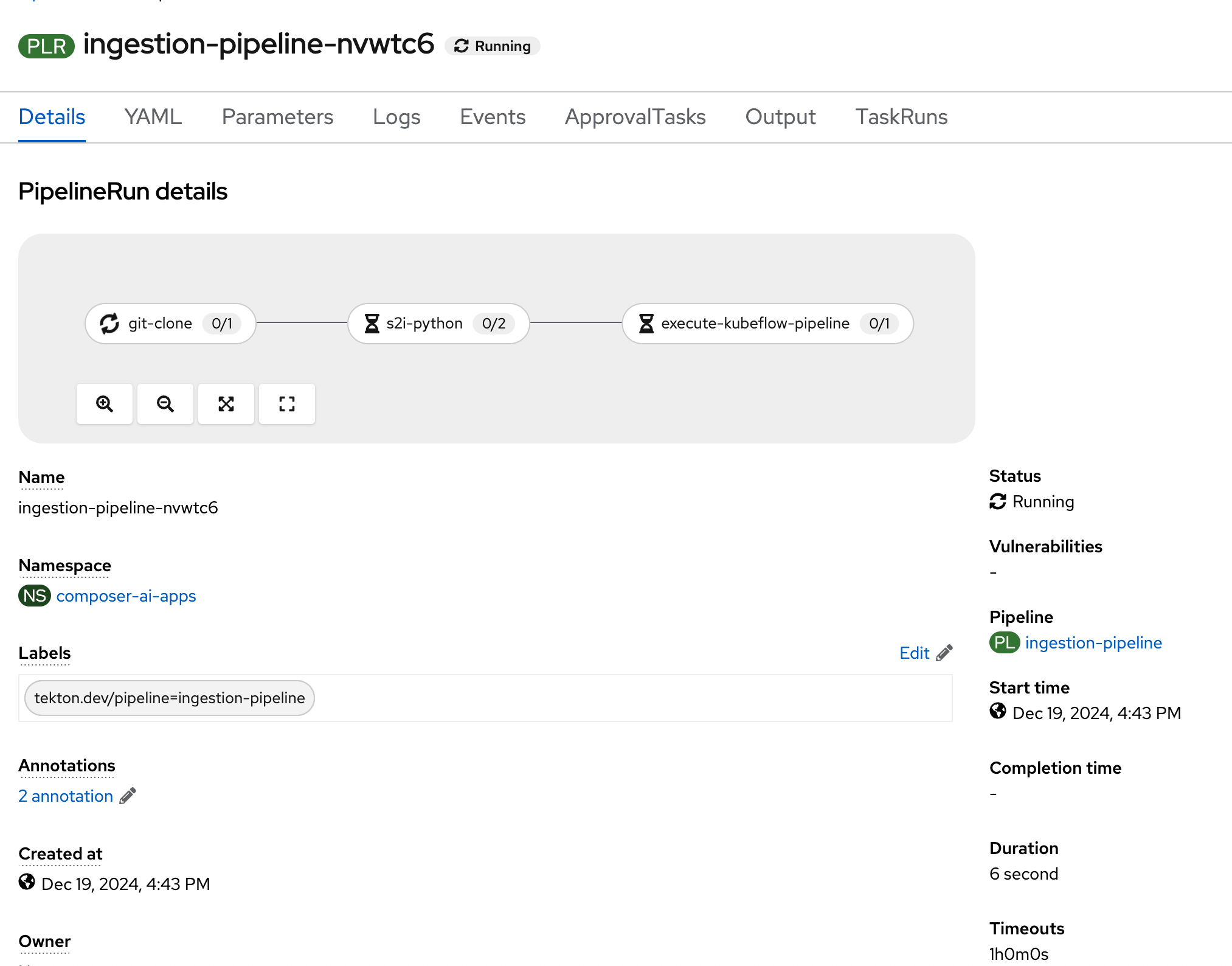
-
A new Data Science Pipeline should have been created and started.
To view the execution, navigate to the OpenShift AI Dashboard and select
Experiments>Experiments and runs.Click on the
document_ingestionexperiment.Make sure you are in the composer-ai-appsProject.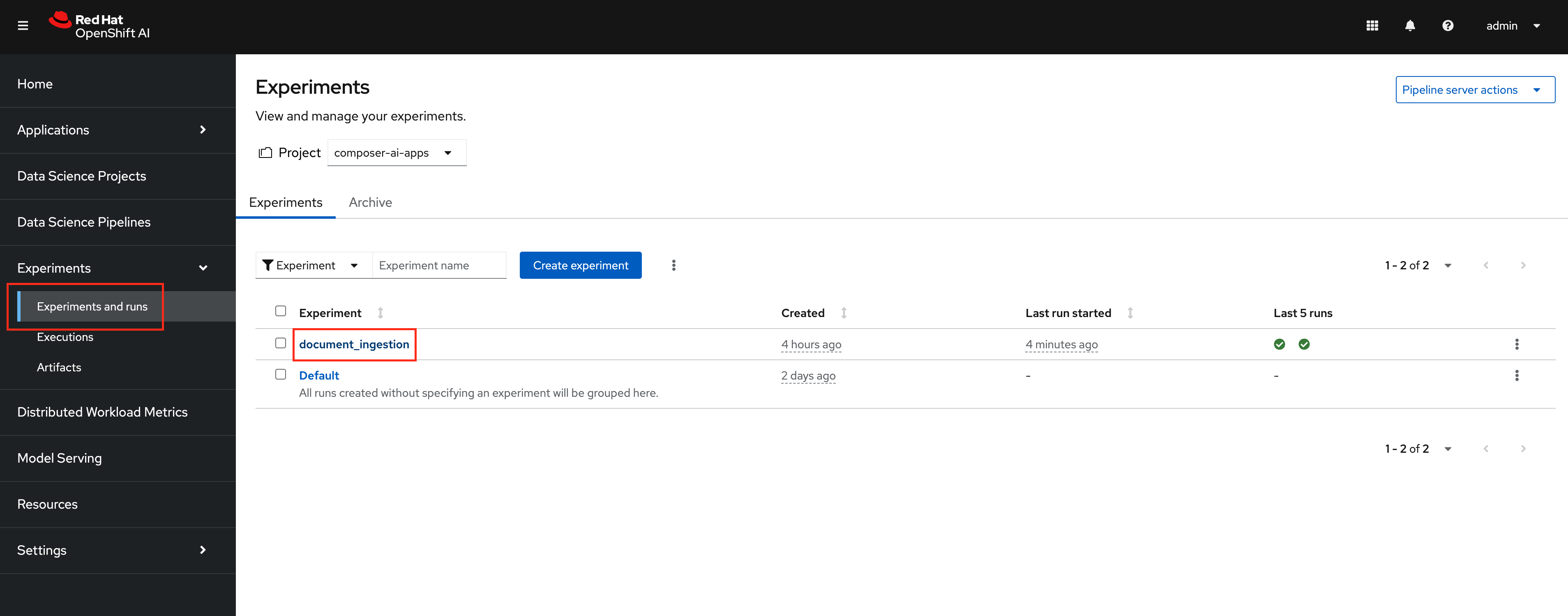
-
You should see a single run listed. Click on the run to view the execution of that run.
The data ingestion process may take several minutes to complete. You can follow the progress of the various steps by checking the
Logsfor each step in the OpenShift AI Dashboard.Some of the steps require a GPU which will trigger a new GPU node to be auto-scaled in your cluster, which can take several minutes (if not already created from before).
-
While this pipeline is completing take a look at the code backing the ingestion pipeline.
Line 17 creates the variable that specifies which product is being ingested, and line 256 set the index name. Can you figure out what index we are pushing too?
Feel free to start reading into the next section
The data ingestion pipeline currently uses a basic chunking algorithm. We are planning future enhancements to make the pipeline more flexible and to improve the chunking algorithm and we are always looking for help!
Specifically, we are investigating the use of docling which should lead to better results.