Environment Overview
In this section, we will review some of the components that are available in this cluster that we will use for this workshop.
Cluster Overview
This OpenShift cluster with the following operators has been deployed:
-
OpenShift AI
-
OpenShift Service Mesh
-
OpenShift Serverless
-
Authorino
-
NVIDIA GPU Operator
-
Node Feature Discovery
-
OpenShift GitOps
-
OpenShift Pipelines
-
Elasticsearch
All of the operators are deployed and managed by a central cluster ArgoCD instance.
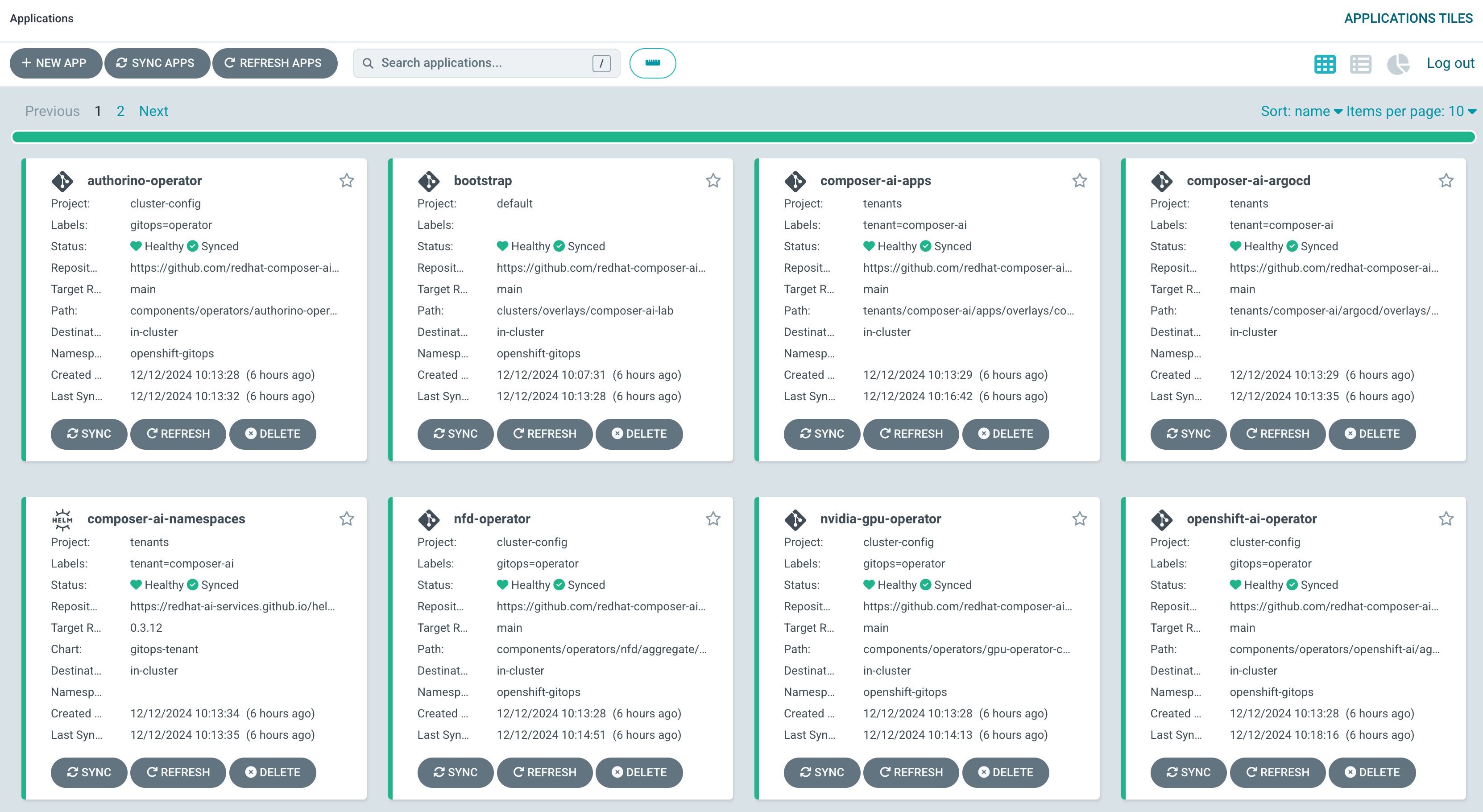
This cluster also is equipped with a single g5.2xlarge node containing an A10G GPU, but it will autoscale additional GPU nodes as we spin up additional resources.
| The repo used to manage the cluster resources can be found here. This repo is based on the AI Accelerator an asset created and maintained by the NA AI Practice for use with deploying and managing OpenShift AI in customer environments. |
Composer AI Overview
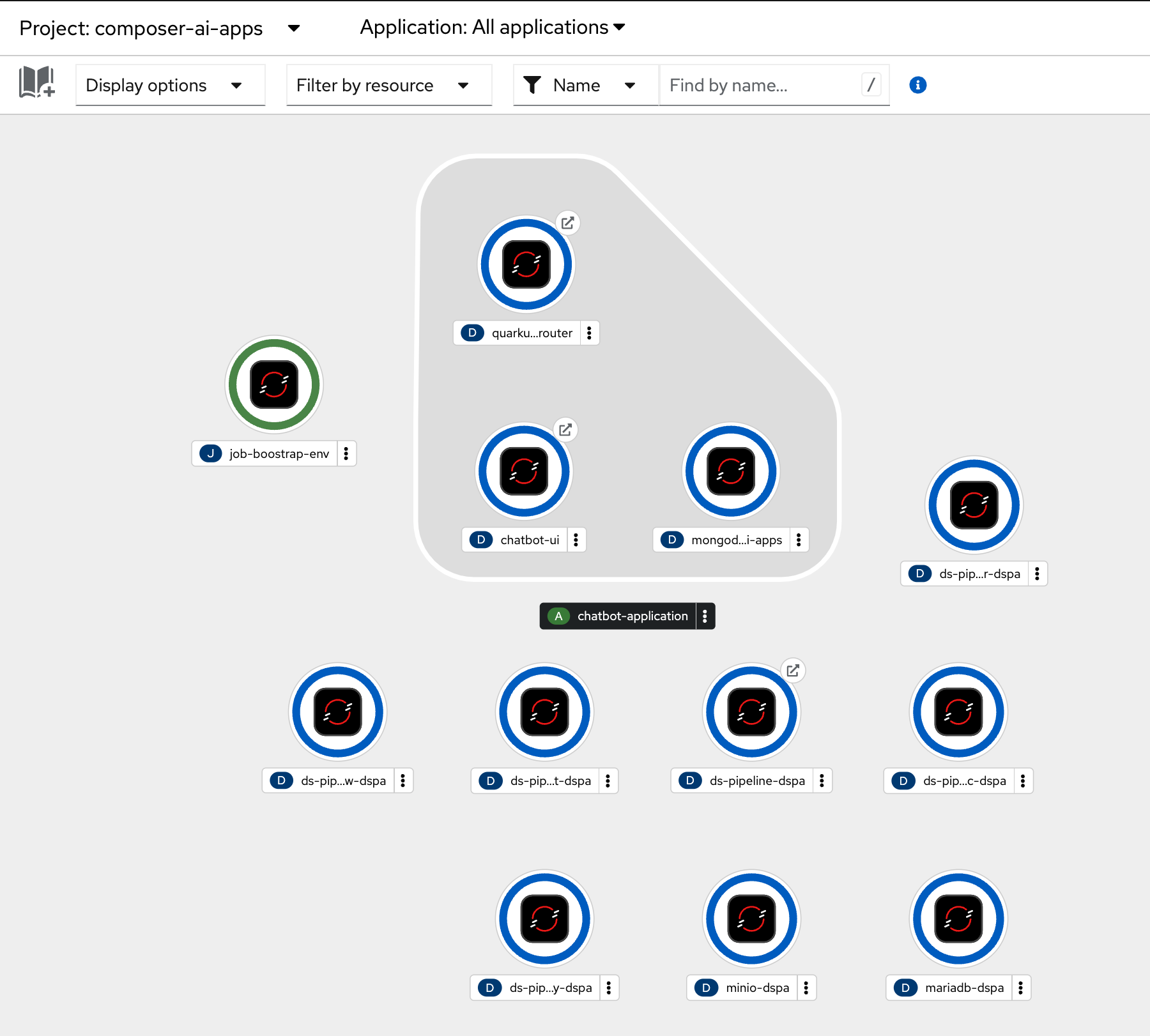
The cluster ArgoCD instance also creates two namespaces, composer-ai-gitops and composer-ai-apps.
An ArgoCD instance deployed to composer-ai-gitops manages all of the resources that are deployed into the composer-ai-apps:
Composer AI is intended to be a tool with a flexible architecture. Allowing for the rapid creation of AI Assistants that can leverage a number of different vector databases and models.
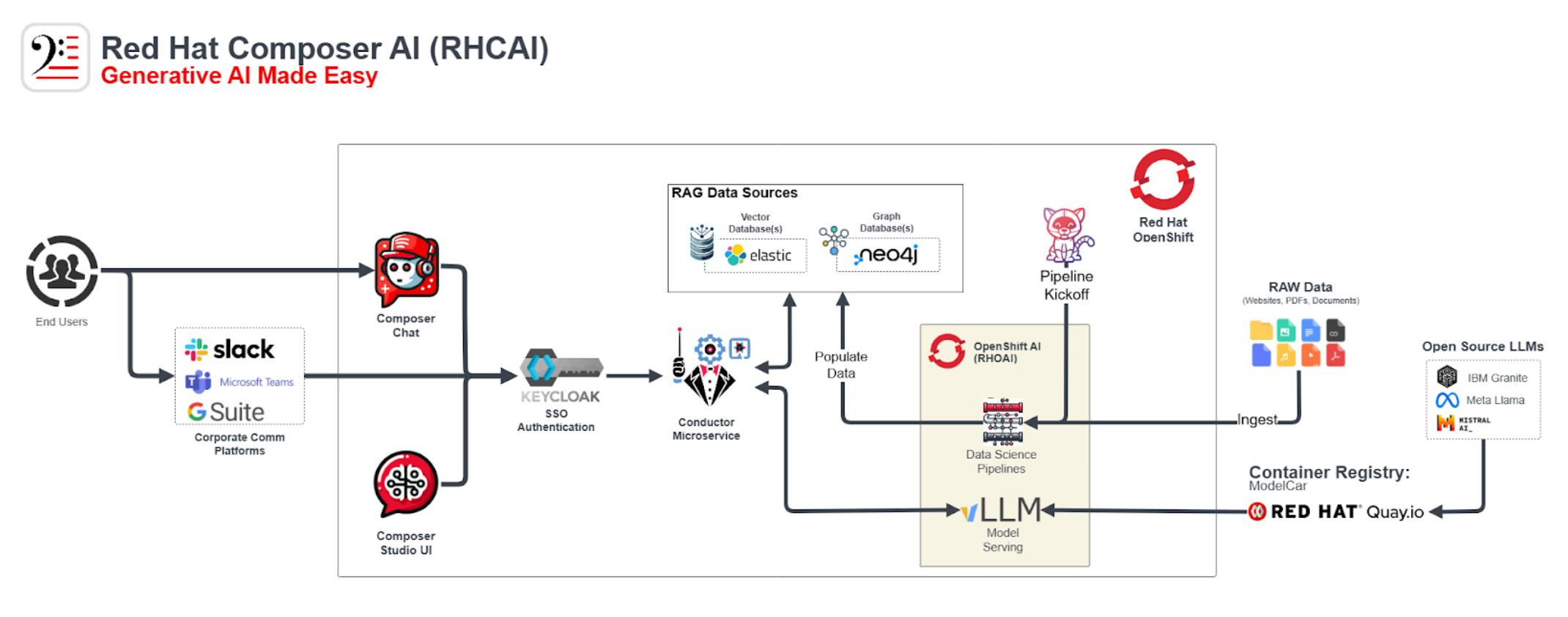
The current deployed applications include the following Composer components:
-
Chat UI with Composer Studio - A PatternFly based web UI designed to allow users to easily interact with the API. Creating new chat assistants and interact with existing assistants.
-
Conductor Microservice - A Quarkus based API that responsible for the management of assistants. Assistants created with Conductor can leverage a RAG pattern with a vector database and various LLMs. Conductor can also act as a gateway for any chat application exposing a rest endpoint.
-
Document Ingestion Pipeline - A pipeline and pipeline patter that allows users to ingest documents into a vector database using both Tekton and Data Science Pipelines
While the Composer AI cluster normally retrieved from demo.redhat.com contains all of the required components to quickly get started with Composer AI, the lab cluster is currently is currently missing a model server and vector database. We will explore those components and how to deploy them as part of this lab.
Our Model Server will be a Granite model using OpenShift AI’s vLLM.
Our Vector Database will an Elasticsearch instance.
Before proceeding, spend a few minutes to familiarize yourself with the various parts of this environment and what has already been deployed.